Новини зірок












Аналіз часових рядів прогноз та управління. Аналіз та прогнозування часових рядів
Надіслати свою гарну роботу до бази знань просто. Використовуйте форму, розташовану нижче
Студенти, аспіранти, молоді вчені, які використовують базу знань у своєму навчанні та роботі, будуть вам дуже вдячні.
Розміщено на http://www.allbest.ru/
Основні методи прогнозування
Методи соціального прогнозування
Методи фінансового прогнозування
Методи економічного прогнозування
Статистичні методи прогнозування
Експертні методи прогнозування
Аналіз часових рядів
Структурні компоненти часового ряду
Основні методи прогнозування
Прогнозування - це передбачення майбутнього на основі накопиченого досвіду та поточних припущень щодо нього.
Прогнозування являє собою складний процес, під час якого необхідно вирішувати велику кількість різних питань. Для його виробництва слід застосовувати у поєднанні різні методи прогнозування, Яких на сьогоднішній день існує безліч, але на практиці використовуються всього 15 - 20. На найбільш популярних з них ми і зупинимося.
Метод експертних оцінок.Суть даного методу полягає в тому, що в основі прогнозу лежить думка одного фахівця або групи спеціалістів, яка ґрунтується на професійному, практичному та науковому досвіді. Розрізняють колективні та індивідуальні експертні оцінки, що часто використовується при оцінці персоналу.
Метод екстраполяції.Основна ідея екстраполяції – вивчення сформованих як у минулому, так і сучасному стійких тенденцій розвитку підприємства та перенесення їх на майбутнє. Розрізняють прогнозну та формальну екстраполяцію. Формальна - ґрунтується на припущенні про те, що в майбутньому збережуться минулі та реальні тенденції розвитку підприємства; при прогнозній - даний розвиток пов'язують із гіпотезами про динаміку підприємства з урахуванням того, що в майбутньому зміниться вплив на нього різних факторів. Слід знати, що методи екстраполяції краще застосовувати на стадії прогнозування, щоб виявити тенденції зміни показників.
Методи моделювання.Моделювання - це конструювання моделі на підставі попереднього вивчення об'єкта та процесів, виділення його суттєвих ознак та характеристик. Прогнозування з використанням моделей включає її розробку, експериментальний аналіз, зіставлення результатів попередніх прогнозних розрахунків з фактичними даними стану процесу або об'єкта, уточнення і коригування моделі.
p align="justify"> Метод економічного прогнозування (економічний аналіз) полягає в тому, що якийсь економічний процес або явище, що мають місце на підприємстві, розчленовуються на частини, після чого виявляється вплив і взаємозв'язок цих частин на хід і розвиток процесу, а також один на одного. За допомогою аналізу можна розкрити сутність такого процесу, а також визначити закономірності його зміни у майбутньому, всебічно оцінити шляхи досягнення поставленої мети. Оскільки економічний аналіз - це необ'ємна частина та один з елементів логіки прогнозування, він має здійснюватися на макро-, мезо- та мікрорівнях. Використовується під час планування виробництва для підприємства. прогнозування економічний тимчасовий експертний
Процес економічного аналізу можна поділити на кілька стадій:
* Постановка проблеми, визначення критеріїв оцінки та цілей;
* підготовка необхідної для аналізу інформації;
* аналітична обробка інформації після її вивчення;
* Оформлення результатів.
Балансовий метод.Даний метод заснований на розробці балансів, які є системою показників, де перша частина, що характеризує ресурси за джерелами їх надходження, дорівнює другий, що відображає розподіл їх по всіх напрямках витрати.
За допомогою балансового способу втілюється в життя принцип пропорційності та збалансованості, який застосовується при розробці прогнозів. Його суть полягає у ув'язуванні потреб підприємства у різних видах сировинних, матеріальних, фінансових та трудових ресурсах з можливостями виробництва продукту та джерелами ресурсів. Таким чином, система балансів, яку використовують у прогнозуванні, включає: фінансові, матеріальні та трудові баланси. У кожну з цих груп входить ще низка балансів.
Нормативний метод- один із основних методів прогнозування. В даний час йому стало надаватися велике значення. Його сутність полягає у техніко-економічних обґрунтуваннях прогнозів з використанням нормативів та норм. Останні застосовуються для розрахунку потреби у ресурсах, і навіть показників їх використання.
Програмно-цільовий метод (ПЦМ).У порівнянні з іншими методами цей метод є порівняно новим і недостатньо розробленим. Він почав широко застосовуватися лише останніми роками. ПЦМ тісно пов'язаний із вже розглянутими методами і передбачає розробку прогнозу починаючи з оцінки підсумкових потреб на підставі цілей розвитку підприємства при подальшому визначенні та пошуку ефективних засобів та шляхів їх досягнення, а також ресурсного забезпечення.
Суть ПМЦ полягає у визначенні основних цілей розвитку підприємства, розробки взаємопов'язаних заходів щодо їх досягнення у заздалегідь визначені терміни при збалансованому забезпеченні ресурсами, а також з урахуванням ефективного їх використання.
Крім прогнозування, ПМЦ застосовується при створенні комплексних цільових програм, які є документом, де відображено мету та комплекс виробничих, організаційно-господарських, соціальних та інших заходів та завдань, пов'язаних за виконавцями, термінами здійснення та ресурсами.
Методи соціального прогнозування
Соціальне прогнозування як дослідження з широким охопленням об'єктів аналізу спирається на множину методів. При класифікації методів прогнозування виділяються основні ознаки, що дозволяють їх структурувати по: ступеня формалізації; принципом дії; способу отримання інформації
Ступінь формалізації у методах прогнозування залежно від об'єкта дослідження може бути різним; способи отримання прогнозної інформації багатозначні, до них слід зарахувати: методи асоціативного моделювання, морфологічний аналіз, ймовірнісне моделювання, анкетування, метод інтерв'ю, методи колективної генерації ідей, методи історико-логічного аналізу, написання сценаріїв тощо. Найбільш поширеними методами соціального прогнозування є методи екстраполяції, моделювання та експертизи.
Екстраполяція означає поширення висновків, що стосуються однієї частини будь-якого явища, іншу частину, явище загалом, у майбутнє. Екстраполяція ґрунтується на гіпотезі про те, що раніше виявлені закономірності діятимуть у прогнозному періоді. Наприклад, висновок про рівень розвитку будь-якої соціальної групи можна зробити за спостереженнями за її окремими представниками, а про перспективи культури – за тенденціями минулого.
Екстраполяційний метод відрізняється різноманіттям - налічує щонайменше п'ять різних варіантів. Статистична екстраполяція – проекція зростання населення за даними минулого – це один із найважливіших методів сучасного соціального прогнозування.
Моделювання – це метод дослідження об'єктів пізнання на їх аналогах – речових чи уявних.
Аналогом об'єкта може бути, наприклад, його макет, креслення, схема тощо. У соціальній сфері найчастіше використовуються уявні моделі. p align="justify"> Робота з моделями дозволяє перенести експериментування з реального соціального об'єкта на його подумки сконструйований дублікат і уникнути ризику невдалого, тим більше небезпечного для людей управлінського рішення. Головна особливість уявної моделі і полягає в тому, що вона може бути схильна до будь-яких випробувань, які практично полягають у тому, що змінюються параметри її самої і середовища, в якому вона (як аналог реального об'єкта) існує. У цьому величезна перевага моделі. Вона може виступити як зразок, свого роду ідеальний тип, наближення якого може бути бажано для творців проекту.
Найпрактикованіший метод прогнозування - експертна оцінка. На думку Є.І.Холостової, «експертиза є дослідження важкоформалізованого завдання, яке здійснюється шляхом формування думки (підготовки висновку) фахівця, здатного заповнити недолік або несистемність інформації з досліджуваного питання своїми знаннями, інтуїцією, досвідом вирішення подібних завдань та опорою на здоровий глузд ».
Існують такі сфери соціального життя, в яких неможливо використовувати інші методи прогнозування, Окрім експертних. Насамперед це стосується тих сфер, де відсутня необхідна та достатня інформація про минуле.
При експертній оцінці стану або окремої соціальної сфери, або її складового елемента, або її компонентів враховується низка обов'язкових положень, методичних вимог.
Насамперед - оцінка вихідної ситуації:
Чинники, що зумовлюють незадовільний стан;
Напрямки, тенденції, найхарактерніші для цього стану ситуації;
Особливості, специфіка розвитку найважливіших складових;
Найбільш характерні форми роботи, засоби, за допомогою яких здійснюється діяльність.
Другий блок питань включає аналіз діяльності тих організацій і служб, які здійснюють цю діяльність. Оцінка їх діяльності йде щодо виявлення тенденцій у їх розвитку, їхнього рейтингу в громадській думці.
Експертну оцінку проводять спеціальні центри експертизи, наукові інформаційно-аналітичні центри, лабораторії експертів, експертні групи та окремі експерти.
Методика експертної роботи включає низку етапів:
Визначається коло експертів;
Виявляються проблеми;
Намічається план та час дій;
Розробляються критерії для експертних оцінок;
Позначаються форми та методи, у яких будуть виражені результати експертизи (аналітична записка, «круглий стіл», конференція, публікації, виступи експертів).
Отже, соціальне прогнозування спирається на різні методи дослідження, основними з яких є екстраполяція, моделювання та експертиза.
Методи фінансового прогнозування
Фінансове прогнозування за методом бюджетування
Процес бюджетування є складовою фінансового планування - процесу визначення майбутніх дій щодо формування та використання фінансових ресурсів.
Бюджетування - процес побудови та виконання бюджету підприємства на основі бюджетів окремих підрозділів.
Бюджет - деталізований план діяльності підприємства на найближчий період, що охоплює дохід від продажу, виробничі та фінансові витрати, рух коштів, формування прибутку підприємства.
Бюджети поділяються на два основні види:
Операційний бюджет, що відбиває поточну (виробничу) діяльність підприємства;
Фінансовий бюджет, що є прогнозом фінансової звітності.
План прибутків та збитків – основний документ операційного бюджету. Містить дані про величину і структуру виручки від продажів, собівартості реалізованої продукції та кінцевих фінансових результатів.
Фінансовий бюджет складається з урахуванням інформації, що міститься у бюджеті про прибутки та збитки.
Однією з основних етапів бюджетування є прогнозування руху коштів.
Бюджет руху коштів - це план грошових надходжень та платежів. При розрахунку бюджету руху коштів важливо визначити час надходжень і платежів, а чи не час виконання господарських операцій.
Значення загального бюджету для підприємства розкривається через такі функції:
Планування операцій, які забезпечують досягнення цілей підприємства;
Координація різних видів діяльності та окремих підрозділів. Погодження інтересів окремих працівників та груп у цілому по підприємству;
Стимулювання керівників всіх рангів для досягнення цілей своїх центрів відповідальності;
Контроль поточної діяльності; забезпечення планової дисципліни;
Основа для оцінки виконання плану центрами відповідальності та їх керівників;
Засіб навчання менеджерів.
На відміну від формалізованих звітів про прибутки та збитки або бухгалтерський баланс, бюджет не має стандартизованої форми, яка повинна суворо дотримуватися. Бюджет може мати нескінченну кількість видів та форм. Форма та структура бюджету залежать від багатьох факторів: масштабу діяльності підприємства; достатності та доступності вихідної інформації; стани нормативної бази підприємства; від кваліфікації та досвіду розробника.
Фінансове прогнозування за методом відсотка від продажів
Існує два основні методи фінансового прогнозування. Один з них – метод бюджетування – представлений у розділі 3 методичних вказівок. Нагадаємо, що він заснований на концепції грошових потоків та його аналогом є розрахунок фінансової частини бізнес-плану.
Другий метод називається метод "відсотка від продажу" (перша модифікація) або метод "формули" (друга модифікація). Його переваги - простота та лаконічність. Застосовується для орієнтовних розрахунків потреби у зовнішньому фінансуванні.
Чинники, які впливають величину потреби у додатковому фінансуванні:
Запланований темпи зростання обсягу реалізації;
Вихідний рівень використання основних засобів;
Капіталоємність (ресурсоємність) продукції;
рентабельність продукції;
Дивідендна політика.
Метод «відсотка від продажу» – метод пропорційної залежності показників діяльності підприємства від обсягу реалізації.
Усі обчислення методом «відсотка від продажу» (методу «формули») робляться з наступних припущень:
1. Змінні витрати, поточні активи та поточні зобов'язання при нарощуванні обсягу продажу на певну кількість відсотків збільшуються в середньому на стільки ж відсотків. Це означає, що і поточні активи, і поточні пасиви становитимуть у плановому періоді колишній відсоток виручки;
2. Відсоток збільшення вартості основних засобів розраховується під заданий відсоток нарощування обороту у відповідність до:
а) технологічними умовами бізнесу;
б) врахуванням наявності недовантажених основних засобів на початок періоду прогнозування;
в) у відповідність до ступеня матеріального та морального зносу готівкових основних засобів тощо;
3. Довгострокові зобов'язання та акціонерний капітал беруться у прогноз незмінними;
4. Нерозподілений прибуток прогнозується з урахуванням норми розподілу чистого прибутку на дивіденди та чистої рентабельності реалізованої продукції.
Для прогнозування нерозподіленого прибутку до нерозподіленого прибутку базового періоду додають прогнозований чистий прибуток та віднімають дивіденди.
Методи економічного прогнозування
p align="justify"> Особливе місце в класифікації методів економічного прогнозування займають так звані комбіновані методи, які об'єднують різні інші методи. Наприклад, колективні експертні оцінки та методи моделювання або статистичні та опитування експертів.
Як інформація використовується фактографічна та експертна інформація.
При класифікації методів прогнозування необхідно пам'ятати, що змістовна систематизація методів прогнозування має визначатися самим об'єктом прогнозування, економічними процесами розвитку та його закономірностями.
З погляду оцінки можливих результатів та шляхів прогнозного науково-технічного розвитку прогнози можна класифікувати за трьома етапами: дослідницьким, програмним та організаційним.
Завданням дослідницького прогнозу є визначення можливих результатів майбутнього розвитку та вибір з безлічі можливих варіантів одного або кількох позитивних результатів. Так, наприклад, розвиток засобів обчислювальної техніки можна відобразити у зростанні їх швидкодії, збільшенні обсягу пам'яті та діапазону логічних можливостей.
Основна мета цього етапу полягає у розкритті широкої гами принципово можливих перспектив у вигляді однієї чи низки науково-технічних проблем, що підлягають вирішенню протягом прогнозованого періоду.
Програмний аспект прогнозу полягає у визначенні можливих шляхів досягнення бажаних та необхідних результатів; очікуваного за часом реалізації кожного з можливих варіантів та ступеня достовірності в успішному досягненні деякого результату за тим чи іншим варіантом.
Організаційна сторона прогнозу включає комплекс організаційно-технічних заходів, які забезпечують досягнення певного результату за тим чи іншим варіантом. В організаційному аспекті виходять з уявлення про готівкові економічні ресурси та накопичений науковий потенціал. Тут має бути сформульована обґрунтована гіпотеза розвитку комплексу організаційних параметрів науки, дана імовірнісна оцінка схеми розподілу ресурсів, що рекомендується, і перспектив зростання наукового потенціалу на прогнозований період.
Розглянуті етапи науково-технічного розвитку, зазвичай, виступають комплексно і у взаємозв'язку.
Статистичні методи прогнозування
Статистичні методи прогнозуванняохоплюють розробку, вивчення та застосування сучасних математико-статистичних методів прогнозування на основі об'єктивних даних (у тому числі непараметричних методів найменших квадратів з оцінюванням точності прогнозу, адаптивних методів, методів авторегресії та інших); розвиток теорії та практики імовірнісно-статистичного моделювання експертних методів прогнозування, у тому числі методів аналізу суб'єктивних експертних оцінок на основі статистики нечислових даних; розробку, вивчення та застосування методів прогнозування в умовах ризику та комбінованих методів прогнозування з використанням спільно економіко-математичних та економетричних (як математико-статистичних, так і експертних) моделей. Наукова база статистичних методів прогнозування - прикладна статистика та теорія прийняття рішень. Найпростіші методи відновлення використовуваних для прогнозування залежності виходять із заданого часового ряду, тобто функції, визначеної в кінцевому числі точок на осі часу. При цьому часовий ряд часто розглядається в рамках тієї чи іншої ймовірнісної моделі, вводяться інші фактори (незалежні змінні), крім часу, наприклад, обсяг грошової маси. Тимчасовий ряд може бути багатовимірним. Основні розв'язувані завдання - інтерполяція та екстраполяція.
Метод найменших квадратів у найпростішому випадку (лінійна функція від одного фактора) був розроблений К. Гауссом у 1794-1795 рр.. Можуть виявитися корисними попередні перетворення змінних, наприклад, логарифмування. Найчастіше використовується метод найменших квадратів за кількох чинників.
Метод найменших модулів, сплайни та інші методи екстраполяції застосовуються рідше, хоча їх статистичні властивості найчастіше кращі. Накопичено досвід прогнозування індексу інфляції та вартості споживчого кошика. Виявилося корисним перетворення (логарифмування) змінної - поточного індексу інфляції. Оцінювання точності прогнозу (зокрема, з допомогою довірчих інтервалів) - необхідна частина процедури прогнозування. Зазвичай використовують імовірнісно-статистичні моделі відновлення залежності, наприклад, будують найкращий прогноз методом максимальної правдоподібності. Розроблено параметричні (зазвичай на основі моделі нормальних помилок) та непараметричні оцінки точності прогнозу та довірчі межі для нього (на основі Центральної Граничної Теореми теорії ймовірностей). Так, запропоновано непараметричні методи довірчого оцінювання точки накладання (зустрічі) двох часових рядів з метою оцінки динаміки технічного рівня власної продукції та продукції конкурентів, представленої на світовому ринку. Застосовуються також евристичні прийоми, не засновані на ймовірності статистичної теорії: метод ковзних середніх, метод експоненційного згладжування.
Багатомірна регресія, у тому числі з використанням непараметричних оцінок щільності розподілу, - основний зараз статистичний апарат прогнозування. Наголосимо, що нереалістичне припущення про нормальність похибок вимірювань та відхилень від лінії (поверхні) регресії використовувати не обов'язково. Однак для відмови від припущення нормальності необхідно спертися на інший математичний апарат, заснований на багатовимірній Центральній Граничній Теоремі теорії ймовірностей, технології лінеаризації та спадкування збіжності. Він дозволяє проводити точкове та інтервальне оцінювання параметрів, перевіряти значущість їхньої відмінності від нуля в непараметричній постановці, будувати довірчі межі для прогнозу. Дуже важливою є проблема перевірки адекватності моделі, а також проблема відбору факторів. Апріорний список факторів, що впливають на відгук, зазвичай дуже великий. Його бажано скоротити, і окремий напрямок сучасних досліджень присвячений методам відбору «інформативної множини ознак». Однак ця проблема поки що остаточно невирішена. Виявляються незвичайні ефекти. Так, встановлено, що оцінки ступеня полінома, що зазвичай використовуються, мають в асимптотиці геометричний розподіл. Перспективними є непараметричні методи оцінювання щільності ймовірності та їх застосування для відновлення регресійної залежності довільного вигляду. Найбільш загальні результати у цій галузі отримані за допомогою підходів статистики нечислових даних. До сучасних статистичних методів прогнозування відносяться також моделі авторегресії, модель Бокса Дженкінса, системи економетричних рівнянь, що ґрунтуються як на параметричних, так і на непараметричних підходах. Для встановлення можливості застосування асимптотичних результатів за кінцевих (т.зв. «малих») обсягів вибірок корисні комп'ютерні статистичні технології. Вони також дозволяють будувати різні імітаційні моделі. Зазначимо корисність методів розмноження даних (бутстрепметодів). Системи прогнозування з інтенсивним використанням комп'ютерів поєднують різні методи прогнозування у межах єдиного автоматизованого робочого місця прогнозиста.
Прогнозування на основі даних, що мають нечислову природу, наприклад, прогнозування якісних ознак, ґрунтується на результатах статистики нечислових даних. Дуже перспективними для прогнозування є регресійний аналіз на основі інтервальних даних, що включає, зокрема, визначення та розрахунок раціонального обсягу вибірки, а також регресійний аналіз нечітких даних. Загальна постановка регресійного аналізу в рамках статистики нечислових даних та її окремі випадки - дисперсійний аналіз та дискримінантний аналіз (розпізнавання образів з учителем), - даючи єдиний підхід до формально різних методів, корисні при програмній реалізації сучасних статистичних методів прогнозування. Основні процедури обробки прогностичних експертних оцінок – перевірка узгодженості, кластер аналіз та перебування групової думки.
Перевірка узгодженості думок експертів, виражених ранжуваннями, проводиться за допомогою коефіцієнтів рангової кореляції Кендалла та Спірмена, коефіцієнта рангової конкордації Кендалла та Сміта. Використовуються параметричні моделі парних порівнянь - Терстоуна, Бредлі Террі Люса - і непараметричні моделі теорії люсіанів. Корисною є процедура узгодження ранжувань та класифікацій шляхом побудови погоджуючих бінарних відносин. За відсутності узгодженості розбиття думок експертів групи подібних між собою проводять методом найближчого сусіда чи іншими методами кластерного аналізу (автоматичного побудови класифікацій, розпізнавання образів без вчителя). Класифікація люсіанів здійснюється на основі імовірнісно-статистичної моделі. Використовують різні методи побудови підсумкової думки комісії експертів. Своєю простотою виділяються методи середніх арифметичних та медіан рангів. Комп'ютерне моделювання дозволило встановити ряд властивостей медіани Кемені, що часто рекомендується для використання як підсумкова (узагальнена, середня) думка комісії експертів у разі, коли їх оцінки дано у вигляді ранжування.
Інтерпретація закону великих чисел для нечислових даних термінах теорії експертного опитування така: підсумкова думка стійко, тобто. мало змінюється за зміни складу експертної комісії, і за зростання кількості експертів наближається до «істини». При цьому передбачається, що відповіді експертів можна розглядати як результати вимірювань з помилками, всі вони - незалежні однаково розподілені випадкові елементи, ймовірність прийняття певного значення зменшується в міру віддалення від деякого центру - "істини", а загальна кількість експертів досить велика. У конкретних завданнях прогнозування необхідно провести класифікацію ризиків, поставити завдання оцінювання конкретного ризику, провести структуризацію ризику, зокрема побудувати дерева причин (в іншій термінології, дерева відмов) та дерева наслідків (деревини подій).
Центральним завданням є побудова групових та узагальнених показників, наприклад, показників конкурентоспроможності та якості. Ризики необхідно враховувати при прогнозуванні економічних наслідків прийнятих рішень, поведінки споживачів та конкурентного оточення, зовнішньоекономічних умов та макроекономічного розвитку Росії, екологічного стану довкілля, безпеки технологій, екологічної небезпеки промислових та інших об'єктів. Сучасні комп'ютерні технології прогнозування засновані на інтерактивних статистичних методи прогнозуваннята використання баз економетричних даних, імітаційних (у тому числі на основі застосування методу статистичних випробувань) та економіко-математичних динамічних моделей, що поєднують експертні, математико-статистичні та моделюючі блоки.
Експертні методи прогнозування
Експерт - кваліфікований спеціаліст, який залучається для формування оцінок щодо об'єкта прогнозування. Експертна група – колектив експертів, сформований за певними правилами. Судження експерта чи експертної групи щодо поставленого завдання прогнозу називається експертною оцінкою; у першому випадку використовується термін "індивідуальна експертна (прогнозна) оцінка", а в другому - "колективна експертна (прогнозна) оцінка". Здатність експерта створювати з урахуванням професійних знань, інтуїції та досвіду достовірні оцінки щодо об'єкта прогнозування характеризує його компетентність. Остання має кількісний захід, званий коефіцієнтом компетентності. Те саме справедливо і щодо експертної групи: компетентність експертної групи - це її здатність створювати достовірні оцінки щодо об'єкта прогнозування, адекватні думці генеральної сукупності експертів; кількісна міра компетентності експертної групи визначається на основі узагальнення коефіцієнтів компетентності окремих експертів, що входять до групи.
Експертний метод прогнозування - метод прогнозування, що базується на експертній інформації. У теоретичному аспекті правомірність використання експертного методу підтверджується тим, що методологічно правильно отримані експертні судження задовольняють двом загальноприйнятим у науці критеріям достовірності будь-якого нового знання: точності та відтворюваності результату. У таблиці дано найменування та короткі характеристики основних експертних методів, що використовуються при розробці соціально-економічних прогнозів.
Аналіз часових рядів
Цілі, методи та етапи аналізу часових рядів
Практичне вивчення часового ряду передбачає виявлення властивостей ряду та отримання висновків про ймовірнісний механізм, що породжує цей ряд. Основні цілі щодо тимчасового ряду такі:
Опис характерних особливостей ряду у стиснутій формі;
Побудова моделі часового ряду;
Пророцтво майбутніх значень на основі минулих спостережень;
Управління процесом, що породжує тимчасовий ряд, шляхом вибірки сигналів, що попереджають про несприятливі події.
Досягнення поставлених цілей можливе далеко не завжди як через брак вихідних даних (недостатня тривалість спостереження), так і через мінливість з часом статистичної структури ряду.
Перелічені цілі диктують значною мірою послідовність етапів аналізу часових рядів:
графічне уявлення та опис поведінки ряду;
виділення та виключення закономірних, невипадкових складових ряду, що залежать від часу;
дослідження випадкової складової часового ряду, що залишилася після видалення закономірної складової;
побудова (підбір) математичної моделі для опису випадкової складової та перевірка її адекватності;
прогнозування майбутніх значень низки.
При аналізі часових рядів використовуються різні методи, найбільш поширеними є:
кореляційний аналіз, використовуваний виявлення характерних особливостей низки (періодичностей, тенденцій тощо. буд.);
спектральний аналіз, що дозволяє знаходити періодичні складові часового ряду;
методи згладжування та фільтрації, призначені для перетворення часових рядів з метою видалення високочастотних та сезонних коливань;
методи прогнозування
Структурні компоненти часового ряду
Як зазначалося, в моделі часового ряду прийнято виділяти дві основні складові: детерміновану і випадкову (рис.1). Під детермінованою складовою часового ряду розуміють числову послідовність, елементи якої обчислюються за певним правилом як функція часу t. Виключивши детерміновану складову з даних, ми отримаємо ряд, що коливається навколо нуля, який може в одному граничному випадку представляти суто випадкові стрибки, а в іншому - плавний коливальний рух. Найчастіше буде щось середнє: деяка иррегулярность і певний систематичний ефект, зумовлений залежністю послідовних членів низки.
У свою чергу детермінована складова може містити такі структурні компоненти:
Тренд g, що є плавною зміною процесу в часі і обумовлений дією довготривалих факторів. Як приклад таких чинників економіки можна назвати: а) зміна демографічних показників популяції (чисельності, вікової структури); б) технологічний та економічний розвиток; в) зростання споживання.
Сезонний ефект s, пов'язаний з наявністю факторів, що діють циклічно із заздалегідь відомою періодичністю. Ряд у цьому випадку має ієрархічну шкалу часу (наприклад, усередині року є сезони, пов'язані з часом року, квартали, місяці) і в однойменних точках ряду мають місце подібні ефекти.
Розміщено на Allbest.ru
...Подібні документи
Сутність економічного прогнозування, характеристика основних форм передбачення. Передбачення внутрішніх та зовнішніх умов діяльності. Види прогнозів та технологія прогнозування. Методи прогнозування: експертні, статистичні, комбіновані.
курсова робота , доданий 22.12.2009
Вивчення методів прогнозування розвитку: екстраполяції, балансового, нормативного та програмно-цільового методу. Дослідження організації роботи експерта, формування анкет та таблиць експертних оцінок. Аналіз математико-статистичних моделей прогнозу.
контрольна робота , доданий 19.06.2011
Поняття, функції та методи прогнозування – науково-обґрунтованого судження про можливі стани об'єкта в майбутньому, про альтернативні шляхи та терміни їх досягнення. Класифікація методів прогнозування: соціосинергетика, "колективна генерація ідей".
курсова робота , доданий 10.03.2011
Сутність основних понять у сфері прогнозування. Ознаки класифікації, види прогнозів та його характеристика. Екстраполятивний та альтернативний підходи. Статистичний та експертний методи, їх різновиди. Зміст та етапи розробки плану збуту.
реферат, доданий 25.01.2010
Сутність та структура системи соціально-економічного прогнозування, види прогнозів та можливості їх застосування для підприємства. Заходи щодо планування діяльності підприємства, їх рівні та призначення. Експертні методи, шляхи прогнозування.
реферат, доданий 27.06.2010
Суть форсайт як методу довгострокового прогнозування. Методи прогнозування, що застосовуються у форсайтах. Критичні технології, експертні панелі. Особливості корпоративного форсайту. Застосування методу корпоративних технологічних "дорожніх карток".
курсова робота , доданий 26.11.2014
Знайомство з основними проблемами прогнозування, способи розв'язання. Згладжуючі моделі прогнозування. Аналіз підходів штучного інтелекту: біологічна аналогія, архітектура мережі, гібридні методи. Робота програми з прогнозу нейронних мереж.
дипломна робота , доданий 27.06.2012
Методи прогнозування, які використовуються в інноваційному менеджменті. Шкали та методи вимірювань в експертному оцінюванні. Організація та проведення експертизи. Отримання узагальненої оцінки з урахуванням індивідуальних оцінок експертів, узгодженість думок.
курсова робота , доданий 07.05.2013
курсова робота , доданий 24.12.2011
Поняття прогнозування та планування. Чому прогнозувати важко. Різні види невизначеностей. Критерії класифікації планування. Основні техніки та види планування. Основні методи прогнозування. Планування як управлінське рішення.
Таблиця Excelз вихідними даними має такий вигляд (рис. 2.33).
Мал. 2.33. Таблиця Excelз вихідними даними
При аналізі часових рядів широко використовуються графічні методи. Це тим, що табличное уявлення часового ряду і описові характеристики найчастіше неможливо зрозуміти характер процесу, а, по графіку часового ряду можна зробити певні висновки, які потім можуть бути перевірені з допомогою розрахунків. Графічний аналіз ряду зазвичай задає напрямок його подальшого аналізу.
Виділимо діапазон осередків А2:К2 і, використовуючи команду Графіквкладки Вставка(рис. 2.34), збудуємо графік (рис. 2.35).

Мал. 2.34. Вкладка Вставка. Команда Графік

Мал. 2.35. Графік - Динаміка продажів автомашин
До вставки лінії тренда отримайте ще чотири копії графіка, щоб кожен тип лінії тренду було побудовано на окремому графіку. Для вставки лінії тренда, клацніть правою кнопкою миші на одному із значень даних графіка та виберіть команду Додати лінію тренду, Як показано на рис. 2.36.

Мал. 2.36. Команда Додати лінію тренду
контекстного меню
У діалоговому вікні Формат лінії тренду(рис. 2.37) вибираються пропоновані типи лінії тренду та активізуються опції показувати рівняння на діаграміі помістити на діаграму величину достовірності апроксимації.

Мал. 2.37. Вибрано параметри лінії тренду
В результаті отримаємо графіки наступного виду (рис. 2.38-2.).

Мал. 2.38. Тип лінії тренду - Лінійна

Мал. 2.39. Тип лінії тренду - Логарифмічна

Мал. 2.40. Тип лінії тренду – Поліноміальна

Мал. 2.41. Тип лінії тренду - Ступінь

Мал. 2.42. Тип лінії тренду – Експонентна
Як апроксимуюча функція обраний поліном другого ступеня – парабола, оскільки має найбільше значення R 2=0,9905, за цим типом тренда і побудований прогноз на два кроки вперед (рис. 2.43). У прикладі прогнозується кількість проданих автомашин на 11 і 12 тижнях (рис. 2.44).

Мал. 2.43. Задано прогноз на два періоди вперед

Мал. 2.44. Прогноз на два періоди вперед
Також для побудови прогнозу можна використовувати вбудовану статистичну функцію ТЕНДЕНЦІЯ. Заповнимо діапазон комірок L1:M1 відповідно числами 11 і 12. Оскільки функція ТЕНДЕНЦІЯ дає масив відповідей, перед її викликом необхідно виділити діапазон відповідей, у разі L2:M2. Використовуючи кнопку Майстри функцій, Викликаємо діалогове вікно функції і заповнимо поля аргументів, як показано на рис. 2.45.

Мал. 2.45. Статистична функція ТЕНДЕНЦІЯ
Після закінчення введення формули: = ТЕНДЕНЦІЯ (B2: K2; B1: K1; L1: M1) натисніть комбінацію клавіш Ctrl+Shift+Enter.
Результат обчислень показаний на рис. 2.46.
Отримали наступний прогноз, якщо підприємство збереже динаміку продажів автомобілів, то на 11-му тижні воно продасть 78 автомашин, а на 12-му тижні - 84.
Лінійна регресія
У таблиці задані два тимчасові ряди: перший їх представляє наростаючий кварталами прибуток комерційного банку ( У), другий ряд – процентну ставку цього банку з кредитування юридичних ( Х) за той же період (табл. 3).
Потрібно:
1. Побудувати однофакторну модель регресії;
2. Оцінити прибуток банку при заданій (приймається користувачем самостійно) процентній ставці;
3. Відобразити на графіку вихідні дані, результати моделювання.
Таблиця 3
Таблиця з вихідними даними в Excelмає такий вигляд (рис. 2.47).

Мал. 2.47. Таблиця з вихідними даними
Для обчислення параметрів моделі складемо розрахункову таблицю такого виду (рис. 2.48).

Мал. 2.48. Розрахункова таблиця
Ця таблиця в режимі індикації формул виглядає так, як показано на наступному рис. 2.49.

Мал. 2.49. Розрахункова таблиця у режимі
індикації формул
У комірки С19 та С20 введені формули для обчислення параметрів а 1і а 0(Рис. 2.50):


Мал. 2.50. Формули для обчислення параметрів а 1і а 0
Значення параметрів наведено на рис. 2.51.

Мал. 2.51. Значення параметрів а 1і а 0
Побудована модель залежності прибутку від величини процентної ставки має вигляд:
Для того щоб визначити прибуток при величині процентної ставки рівної 30%, необхідно підставити значення хотриману модель.
У комірку С22 введено таку формулу (рис 2.52):

Мал. 2.52. Формула для обчислення прогнозної величини прибутку
Прогнозне значення прибутку становитиме 13 тис. руб. (Рис. 2.53).

Мал. 2.53. Прогнозне значення прибутку
Розрахуємо таблицю залишків (рис. 2.54).

Мал. 2.54. Таблиця залишків
Таблиця залишків у режимі індикації формул має такий вигляд (рис. 2.55).

Мал. 2.55. Таблиця залишків у режимі індикації формул
Величина відхилення від лінії регресії обчислюється за такою формулою:
У комірку С38 введено формулу для обчислення величини відхилення з використанням вбудованої математичної функції КОРІНЬ (рис. 2.56).

Мал. 2.56. Вбудована математична функція КОРІНЬ
Розмір відхилення від лінії регресії становить 3,4401 (рис. 2.57).

Мал. 2.57. Величина відхилення від лінії регресії
На наступному етапі розраховуються верхня межа прогнозу та нижня. Для розрахунку довірчого інтервалу скористаємося такою формулою:
 ,
,
яка введена в комірку С40.
Коефіцієнт t aє табличним значенням t- Статистики Стьюдента при заданому рівні значущості aта числі спостережень. Якщо задати ймовірність влучення прогнозованої величини всередину довірчого інтервалу, що дорівнює 90% ( a= 0,01), число ступенів свободи df= 10-1-1, то t a=1,8595.
Значення U = 6,804 (рис. 2.58).
Мал. 2.58. Розмір довірчого інтервалу
Для розрахунку верхньої та нижньої меж прогнозу відповідно вводимо в комірки С42 і С43 формули, як показано на наступному рис. 2.59.

Мал. 2.59. Формули для розрахунку меж прогнозу
Верхня межа прогнозу дорівнює 19,81 тис. руб., Нижня - 6,20 тис. руб. (Рис. 2.60).

Мал. 2.60. Значення меж прогнозу
Графік вихідних даних та результати моделювання наведено на рис. 2.61.
 Мал. 2.61. Графік моделі парної регресії
Мал. 2.61. Графік моделі парної регресії
Для обчислення параметрів моделі можна було також використовувати вбудовані статистичні функції, такі як НАКЛОН, ВІДРІЗОК, ЛІНІЙН, СТОШУХ та ін.
Функція НАКЛОН обчислює нахил лінії регресії, у прикладі це параметр а 1.
Функція ВІДРІЗОК обчислює параметр а 0.
Функція Лінейн одночасно обчислює обидва ці параметри. Перед введенням функції необхідно виділити діапазон відповідей (дві осередки), а після заповнення аргументів функції натиснути комбінацію клавіш Ctrl+Shift+Enter.
Функція СТОШУХ обчислює стандартну помилку, у прикладі це величина S y.
Діалогове вікно вбудованої статистичної функції НАКЛОН із введеними аргументами показано на рис. 2.62.

Мал. 2.62. Вбудована статистична функція НАХОД
Діалогове вікно вбудованої статистичної функції ВІДРІЗОК із введеними аргументами показано на рис. 2.63.

Мал. 2.63. Вбудована статистична функції ВІДРІЗОК
Діалогове вікно вбудованої статистичної функції Лінейн з введеними аргументами показано на рис. 2.64.

Мал. 2.64. Вбудована статистична функція Лінейн
Діалогове вікно вбудованої статистичної функції СТОШУХ із введеними аргументами показано на рис. 2.65.

Мал. 2.65. Вбудована статистична функція СТОШУХ
Результат обчислень з вбудованих статистичних функцій показано на рис. 2.65.

Мал. 2.66. Результат обчислень щодо вбудованих статистичних функцій
Також для побудови моделі можна використовувати вбудований інструмент Пакету аналізу Регресія. Для цього на вкладці Данівиберіть команду Аналіз даних(Рис. 2.67).

Мал. 2.67. Вкладка Дані. Команда Аналіз даних
У діалоговому вікні, що з'явилося. Аналіз данихвиберіть інструмент Регресія(Рис. 2.68).

Мал. 2.68. Діалогове вікно Аналіз даних.
Інструмент Регресія
Заповніть аргументи діалогового вікна Регресія, Як показано на рис 2.69.

Мал. 2.69. Параметри інструменту Регресія
Excelзгенерує лист звіту, що містить такі таблиці:
· Регресійна статистика (рис. 2.70);
· Дисперсійний аналіз (рис. 2.71 - 2.72);
· Таблиця залишків (рис. 2.73),
а також збудує графік залишків (рис. 2.74).

Мал. 2.70. Регресійна статистика

Мал. 2.71. Дисперсійний аналіз

Мал. 2.72. Дисперсійний аналіз. значення коефіцієнтів

Мал. 2.73. Виведення залишку
Графік залишків має такий вигляд (рис. 2.74).

Мал. 2.74. Графік залишків
При виконанні цього завдання значення коефіцієнтів рівняння парної регресії а 1і а 0визначалися трьома способами: методом найменших квадратів, за допомогою вбудованих статистичних функцій та використовуючи інструмент Регресія. У кожному випадку було отримано той самий результат, що говорить про правильність розрахунку цих параметрів.
Методи прогнозування часових рядів
1. Прогнозування як завдання аналізу часового ряду. Детермінована та випадкова складові: способи їх виділення та оцінки.
Прогнозування – це наукове виявлення ймовірнісних шляхів та результатів подальшого розвитку явищ і процесів, оцінка показників процесів більш-менш віддаленого майбутнього.
Зміна стану явища (процесу), що спостерігається, характеризується сукупністю параметрів x1, x2, … , xt,…, виміряних у послідовні моменти часу. Така послідовність називається тимчасовим рядом.
Аналіз часових рядів – один із напрямів науки прогнозування.
Якщо одночасно розглядаються кілька характеристик процесу, то цьому випадку говорять про багатовимірні тимчасові ряди.
Під детермінованою (закономірною) складовою часового ряду x1, x2, …, xn розуміється числова послідовність d1, d2, …, dn, елементи якої обчислюються за певним правилом як функція часу t.
Якщо виключити з ряду детерміновану складову, то частина буде виглядати хаотично. Її називають випадковою компонентою ε1, ε2, …, εn.
Моделі розкладання часового ряду на детерміновану та випадкову компоненти:
1. Адитивна модель:
xt = dt + εt, t = 1, ... n
2. Мультиплікативна модель:
xt = dt · εt, t = 1, ... n
Якщо мультиплікативну модель прологарифмувати, отримаємо адитивну модель для логарифмів xt.
У детермінованому компоненті виділяють:
1) Тренд (trt) – нециклічна компонента, що плавно змінюється, що описує чистий вплив довготривалих факторів, ефект яких позначається поступово.
2) Сезонна компонента (St) – відбиває повторюваність процесів у часі.
3) Циклічна компонента (Ct) – визначає тривалі періоди відносного підйому та спаду.
4) Інтервенція – істотне короткочасне вплив на тимчасовий ряд.
Моделі тренду:
- Лінійна: trt = b0 + b1t
- Нелінійні моделі:
поліноміальна: trt = b0 + b1t + b2t2 + … + bntn
логарифмічна: trt = b0 + b1 ln(t)
логістична:
експонентна: trt = b0 · b1t
параболічна: trt = b0 + b1t + b2t2
гіперболічна: trt = b0 + b1 / t
Тренд використається для довгострокового прогнозу.
Виділення тренду:
1) Метод найменших квадратів (час – фактор, часовий ряд – залежна змінна):
xti = f (ti, θ) + εt i = 1, ... n
f – функція тренду;
θ – невідомі параметри моделі часового ряду.
εt – незалежні та однаково розподілені випадкові величини.
Якщо мінімізувати функцію, можна знайти параметри θ.
2) Застосування різницевих операторів
![]()
Виділення сезонних ефектів
Нехай m – кількість періодів, p – величина періоду.
St = St + p, для будь-яких t.
1) Оцінка сезонної компоненти
а) Сезонні ефекти на тлі тренду
Для адитивної моделі xt = trt + St + εt оцінка:
Якщо необхідно, щоб сума сезонних ефектів дорівнювала 0, то переходять до скоригованих оцінок сезонних ефектів:

Для мультиплікативної моделі xt = trt * St * εt:

б) За наявності в ряді циклічної компоненти (метод ковзних середніх)
Ідея методу: кожне значення вихідного ВР замінюється середнім значенням на інтервалі часу, довжина якого вибирається заздалегідь. Вибраний інтервал ніби ковзає вздовж ряду.
Ковзне середнє при медіанному згладжуванні: t=med (xt-m, xt-m+1, …, xt+m)
При середньо арифметичному згладжуванні:
xt=1/(2m+1)(xt-m+xt-m+1+…+xt+m), якщо р – парний,
xt=1/(2m)(1/2*xt-m+xt-m+1+…+1/2*xt+m) якщо р – непарний.
Для адитивної моделі xt = trt + Ct + St + εt.
Для спрощення позначень: почнемо нумерацію величин з одиниці, змінимо нумерацію вихідного ряду так, щоб величина x відповідала член xt.
– ковзне середнє з періодом p, побудоване xt.
Для мультиплікативної моделі – перейти до логарифмів та отримати мультиплікативну модель.
xt = trt · Ct · St · εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Видалення сезонної компоненти (сезонне вирівнювання)
а) За наявності оцінок сезонної компоненти:
Для адитивної моделі – шляхом віднімання з початкових значень ряду отриманих сезонних оцінок.
Для мультиплікативної моделі – шляхом розподілу початкових значень ряду на відповідні сезонні оцінки та множенням на 100%.
б) Застосування різницевих операторів
де В - оператор зсуву назад.
Різнивний оператор другого порядку:
Якщо ВР одночасно містить тренд і сезонну компоненту, їх видалення можливе за допомогою послідовного застосування простих і сезонних різницевих операторів. Порядок їх застосування не суттєвий:
3) Прогнозування за допомогою сезонної компоненти:
Для адитивної моделі:
![]()
Для мультиплікативної моделі:

2. Моделі часового ряду: AR(p), MA(q), ARIMA(p,d,q). Ідентифікація моделей, оцінка параметрів, дослідження адекватності моделі, прогнозування.
Для опису ймовірності компоненти часового ряду використовують поняття випадкового процесу.
Випадковим процесом x(t), заданим на множині Т, називають функцію від t, значення якої при кожному t є випадковою величиною.
Випадкові процеси, у яких ймовірнісні властивості не змінюються у часі, називаються стаціонарними (маточкування та дисперсія – константи).
Як модель стаціонарних часових рядів найчастіше використовуються:
Ковзне середнє;
Їхні комбінації.
Для перевірки стаціонарності низки залишків та оцінки його дисперсії використовують:
Вибіркову автокореляційну функцію (корелограму);
Приватна автокореляційна функція.
Нехай εt – процес білого шуму, тобто. різні моменти часу t випадкові величини εt незалежні і однаково розподілені з параметрами M(εt)=0, D(εt)=σ2=const. Тоді:
Випадковий процес x(t) із середнім значенням μ називається процесом авторегресії порядку p (AR(p)), якщо для нього виконується співвідношення:
x(t)-μ= α1 (x(t-1) – μ) + α2 (x(t-2) – μ) +…+ αp (x(t-p) – μ) + εt
Випадковий процес x(t) називається процесом ковзного середнього порядку q (MA(q)), якщо для нього виконується співвідношення:
x(t)= εt + β1 εt-1 +…+ βq εt-q
Випадковий процес x(t) називається процесом авторегресії-ковзного середнього порядків p і q (ARMA(p,q)), якщо для нього виконується співвідношення:
Нестаціонарні технічні та економічні процеси можна описати модифікованою моделлю ARMA(p,q). Для видалення тренда можна використовувати різницеві оператори.
Нехай дані дві послідовності U=(…,U-1,U0,U1,…) і V=(…,V-1, V0,V1,V2,…) такі, що:
Значить для
![]() означає і т.д.
означає і т.д.
Тоді процес AR(p) представляється у вигляді ,
MA(q): ![]() ,
,
ARMA(p,q): ![]()
B можна використовувати як оператор різниці, тобто. ![]()
еквівалентно V=(1-B)U
Для різниці другого порядку:
z = (1-B) V = (1-B) 2U

де – різницевий оператор порядку d; x=(1-B)dx.
Ідентифікувати модель – визначити її параметри p, d та q. Для ідентифікації моделі є графіки приватних автокореляційних (АКФ) і приватних автокореляційних функцій (ЧАКФ).
АКФ. k-й член АКФ визначається за такою формулою:
 (*)
(*)
Параметр k називають лагом. На практиці k< n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
Значення ЧАКФ знаходять, вирішуючи систему Юла - Уолкера, використовуючи значення АКФ
Система Юла – Волкера:
R1 = a1 + a2 * r1 + ... + ap * rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ ap
Після візуалізації ряду та видалення тренда розглядається АКФ. Якщо графік АКФ немає тенденції до згасання, це нестаціонарний процес (модель ARIMA). За наявності сезонних коливань корелограма містить періодичні сплески, зазвичай відповідні періоду коливань. Розглядаються різниці 1-го, 2-го, ... k-го порядку, поки ряд не стане стаціонарним, тоді параметр d = k (зазвичай k не більше 2). Переходять до ідентифікації стаціонарної моделі.
Ідентифікація стаціонарних моделей:
АКФ плавно спадає;
ЧАКФ обривається на лазі p.
АКФ обривається на лазі q.
ЧАКФ плавно спадає.
Оцінка параметрів m, ai моделі AR(p):
Як оцінку m можна взяти середнє значення ВР
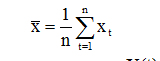
Для оцінки ai знайдемо кореляцію між X(t) та X(t-k):
Загальне рішення цього рівняння щодо rk визначається корінням характеристичного рівняння
Нехай коріння характеристичного рівняння різне. Тоді загальне рішення може бути записане у вигляді:
З вимоги стаціонарності випливає, що це |λi|<1.
Якщо записати рівняння (**) для k = 1, 2, 3 ..., отримаємо систему Юла-Уоркера для AR (p) процесу:
r1 = a1 + a2 * r1 + … + ap * rp-1
r2 = a1 * r1 + a2 + ... + ap * rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ap
Вирішуючи цю систему щодо a1, a2....ap, отримаємо параметри AR(p).
Оцінка параметра βi моделі MA(q):
Для процесу МА(q) при | k | > q Cov = 0.
Cov = s2*(bk + b1*bk+1 + b2*bk+2 + … + bq-k*bq)
Звідси автокореляційна функція має вигляд:
 (***)
(***)
Для оцінювання коефіцієнтів bi по спостеріганій ділянці траєкторії існує кілька шляхів. Найбільш простий:
Знаходять коефіцієнти кореляції ![]() за формулою (*). З системи (***) одержують систему нелінійних рівнянь для знаходження bi. Вона вирішується ітераційними методами.
за формулою (*). З системи (***) одержують систему нелінійних рівнянь для знаходження bi. Вона вирішується ітераційними методами.
Прогнозування. При прогнозуванні необхідно отримати детерміновані значення ВР за формулами, що вже є, а потім розрахувати випадкові значення за підібраною моделлю і скоригувати детерміновані значення на величину випадкових значень.
3. Прогнозування з допомогою штучних нейронних мереж, метод вікон.
Розв'язання математичних завдань з допомогою нейронних мереж (НС) здійснюється шляхом навчання НС способів розв'язання цих завдань.
Навчання багатошарової нейронної мережі проводиться шляхом зворотного поширення помилки (Back Propagation).
Модель штучного нейрона

де xi - Вхідні сигнали,
ai – коефіцієнти провідності (const), які коригуються у процесі навчання,
F – функція активації, вона нелінійна, у різних моделях може бути по-різному. Наприклад, «сигмоїда»:
Загальна структура нейронної мережі:
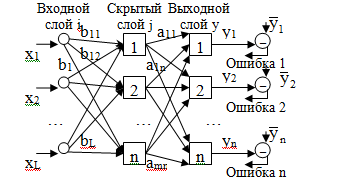
Прихованих шарів може бути кілька, тому СР - багатошарова.
- Вектор еталонних сигналів (бажаних)
yi – вектор реальних (вихідних) сигналів
xi - Векторний вхідних сигналів.
Стратегія навчання «навчання з учителем»
Типові кроки:
1) Вибрати чергову навчальну пару з навчальної множини.
x – вхідний вектор;
- Відповідний йому бажаний (вихідний вектор).
Подати вхідний вектор х на вхід СР.
2) Обчислити вихід мережі у – реальний вихідний сигнал.
Попередньо, вагові коефіцієнти aij і bij задаються довільно випадковим чином.
3) Обчислити відхилення (помилку): ![]()
4) Підкоригувати ваги aij та bij мережі так, щоб мінімізувати помилку.
![]()
5) Повторити кроки 1-4.
Процес повторюється до тих пір, поки помилка на всій навчальній множині не зменшиться до необхідної величини.
Прохід вперед сигналу X по мережі:
З навчальної множини береться пара. До кожного шару, починаючи з першого, обчислюється Y: Y = F(X·A),
де A – матриця ваги шару;
F – функція активації.
Обчислення – шар за шаром.
Зворотний прохід помилки по СР:
Виконується підстроювання ваги вихідного шару. Для цього застосовується дельта-правило, що модифікується.
Мал. Навчання однієї ваги від нейрона p у прихованому шарі j до нейрона q у вихідному шарі k
Для вихідного нейрона спочатку знаходиться сигнал помилки
![]()
εq множиться на похідну функції, що стискає , обчислену для цього нейрона шару k. Отримуємо величину δ:
Δapqk = α · δqk · ypj,
де α – коефіцієнт швидкості навчання (0.01≤ α<1) – const, подбирается экспериментально в процесса обучения.
ypj - Вихідний сигнал нейрона p шару j.
 – величина ваги у зв'язці нейронів p→q на кроці t (до корекції) та кроці t+1 (після корекції).
– величина ваги у зв'язці нейронів p→q на кроці t (до корекції) та кроці t+1 (після корекції).
Підстроювання ваг прихованого шару.
Розглянемо нейрон прихованого шару p. При переході вперед цей нейрон передає свій вихідний сигнал нейронам вихідного шару через ваги, що з'єднують їх. Під час навчання ці ваги функціонують у зворотному порядку, пропускаючи величину від виходу назад до прихованого шару.

І так для кожної пари. Процес закінчується, якщо для кожного X НС вироблятиме
Прогнозування за допомогою СР. Метод вікон.
Заданий часовий ряд xt, t=1,2…T. Завдання прогнозування зводиться до завдання розпізнавання образів на СР.
Метод виявлення закономірності в часовому ряді на основі СР називається “windowing” (метод вікон).
Використовується два вікна Wi (input) і Wo (output) фіксованого розміру n і m відповідно, для безлічі даних, що спостерігається.

Ці вікна здатні переміщатися з деяким кроком S кривою (рядом) вздовж осі часу. В результаті виходить деяка послідовність спостережень:

Перше вікно Wi, сканує дані, зраджує їх на вхід СР, а Wo - на вихід. Пара, що виходить на кожному кроці Wji→Wj0, j=1..n утворює навчальну пару (спостереження). Після навчання СР можна використовувати для прогнозу.
У трьох попередніх нотатках описані регресійні моделі, що дозволяють прогнозувати відгук за значеннями змінних, що пояснюють. У цій замітці ми покажемо, як за допомогою цих моделей та інших статистичних методів аналізувати дані, зібрані протягом послідовних часових інтервалів. Відповідно до особливостей кожної компанії, згаданої у сценарії, ми розглянемо три альтернативні підходи до аналізу часових рядів.
Матеріал буде проілюстрований наскрізним прикладом: прогнозування доходів трьох компаній. Уявіть собі, що ви працюєте аналітиком у великій фінансовій компанії. Щоб оцінити інвестиційні перспективи своїх клієнтів, необхідно передбачити доходи трьох компаній. Для цього ви зібрали дані про три цікаві для вас компанії - Eastman Kodak, Cabot Corporation і Wal-Mart. Оскільки компанії розрізняються за видом ділової активності, кожен тимчасовий ряд має свої унікальні особливості. Отже, для прогнозування необхідно застосовувати різні моделі. Як вибрати найкращу модель прогнозування для кожної компанії? Як оцінити інвестиційні перспективи з урахуванням результатів прогнозування?
Обговорення розпочинається з аналізу щорічних даних. Демонструються два методи згладжування таких даних: ковзне середнє та експоненційне згладжування. Потім демонструється процедура обчислення тренду за допомогою методу найменших квадратів та складніші методи прогнозування. Насамкінець, ці моделі поширюються на тимчасові ряди, побудовані з урахуванням щомісячних чи щоквартальних даних.
Завантажити нотатку у форматі або , приклади у форматі
Прогнозування у бізнесі
Оскільки економічні умови з часом змінюються, менеджери повинні прогнозувати вплив, який ці зміни вплинуть на їхню компанію. Одним із методів, що дозволяють забезпечити точне планування, є прогнозування. Незважаючи на велику кількість розроблених методів, всі вони мають ту саму мету - передбачити події, які відбудуться в майбутньому, щоб врахувати їх при розробці планів і стратегії розвитку компанії.
Сучасне суспільство постійно відчуває потребу у прогнозуванні. Наприклад, щоб виробити правильну політику, урядовці повинні прогнозувати рівні безробіття, інфляції, промислового виробництва, прибуткового податку окремих осіб та корпорацій. Щоб визначити потреби в обладнанні та персоналі, директори авіакомпаній повинні правильно передбачити обсяг авіаперевезень. Для того, щоб створити достатню кількість місць у гуртожитку, адміністратори коледжів чи університетів хочуть знати, скільки студентів надійдуть до їхнього навчального закладу наступного року.
Існують два загальноприйняті підходи до прогнозування: якісний та кількісний. Методи якісного прогнозування є особливо важливими, якщо досліднику недоступні кількісні дані. Як правило, ці методи мають дуже суб'єктивний характер. Якщо статистику доступні дані історії об'єкта дослідження, слід застосовувати методи кількісного прогнозування. Ці методи дозволяють передбачити стан об'єкта у майбутньому з урахуванням даних про його минуле. Методи кількісного прогнозування поділяються на дві категорії: аналіз часових рядів та методи аналізу причинно-наслідкових залежностей.
Тимчасовий ряд- це набір числових даних, одержаних протягом послідовних періодів часу. Метод аналізу часових рядів дозволяє передбачити значення числової змінної на основі її минулих та справжніх значень. Наприклад, щоденні котирування акцій на Нью-Йоркській фондовій біржі утворюють тимчасовий ряд. Іншим прикладом часового ряду є щомісячні значення індексу споживчих цін, щоквартальні величини валового внутрішнього продукту та щорічні доходи від продажу якоїсь компанії.
Методи аналізу причинно-наслідкових залежностейдозволяють визначити, які чинники впливають значення прогнозованої змінної. До них відносяться методи множинного регресійного аналізу із змінними, що запізнюються, економетричне моделювання, аналіз лідируючих індикаторів, методи аналізу дифузійних індексів та інших економічних показників. Ми розповімо лише про методи прогнозування на основі аналізу часів ых рядів.
Компоненти класичної мультиплікативної моделі часу ых рядів
Основне припущення, що лежить в основі аналізу часових рядів, полягає в наступному: фактори, що впливають на досліджуваний об'єкт у теперішньому та минулому, впливатимуть на нього та в майбутньому. Таким чином, основні цілі аналізу часових рядів полягають у ідентифікації та виділенні факторів, що мають значення для прогнозування. Щоб досягти цієї мети, було розроблено багато математичних моделей, призначених для дослідження коливань компонентів, що входять до моделі часового ряду. Ймовірно, найпоширенішою є класична мультиплікативна модель для щорічних, щоквартальних та щомісячних даних. Для демонстрації класичної мультиплікативної моделі часових рядів розглянемо дані фактичних доходах компанії Wm.Wrigley Jr. Company за період з 1982 по 2001 роки (рис. 1).
Мал. 1. Графік фактичного валового прибутку компанії Wm.Wrigley Jr. Company (млн. дол. у поточних цінах) за період з 1982 по 2001 роки
Як бачимо, протягом 20 років фактичний валовий дохід компанії мав зростаючу тенденцію. Ця довготривала тенденція називається трендом. Тренд- не єдиний компонент часового ряду. Крім нього, дані мають циклічний та нерегулярний компоненти. Циклічний компонентописує коливання даних вгору та вниз, часто корелюючи з циклами ділової активності. Його довжина змінюється в інтервалі від 2 до 10 років. Інтенсивність, або амплітуда, циклічного компонента також непостійна. У деякі роки дані можуть бути вищими за значення, передбачене трендом (тобто перебувати в околиці піку циклу), а в інші роки - нижче (тобто бути на дні циклу). Будь-які дані, що спостерігаються, не лежать на кривій тренда і не підпорядковуються циклічній залежності, називаються іррегулярними або випадковими компонентами. Якщо дані записуються щодня або щокварталу, виникає додатковий компонент, що називається сезонним. Усі компоненти часових рядів, притаманних економічних додатків, наведено на рис. 2.

Мал. 2. Чинники, що впливають на тимчасові ряди
Класична мультиплікативна модель часового ряду стверджує, що будь-яке значення є добутком перелічених компонентів. Якщо дані є щорічними, спостереження Yi, відповідне i-му році, виражається рівнянням:
(1) Y i = T i* C i* I i
де T i- значення тренду, C i i-му році, I i i-му році.
Якщо дані вимірюються щомісяця чи щокварталу, спостереження Y i, Що відповідає i-му періоду, виражається рівнянням:
(2) Y i = T i *S i *C i *I i
де T i- значення тренду, S i- значення сезонного компонента в i-ом періоді, C i- значення циклічного компонента в i-ом періоді, I i- значення випадкового компонента в i-ом періоді.
У першому етапі аналізу часових рядів будується графік даних, і виявляється їх залежність від часу. Спочатку необхідно з'ясувати, чи існує довготривале зростання або спадання даних (тобто тренд), чи тимчасовий ряд коливається навколо горизонтальної лінії. Якщо тренд відсутній, то для згладжування даних можна застосувати метод ковзних середніх чи експоненційного згладжування.
Згладжування річних тимчасових рядів
У сценарії ми згадали про Cabot Corporation. Маючи штаб-квартиру в Бостоні, штат Массачусетс, вона спеціалізується на виробництві та продажу хімікатів, будівельних матеріалів, продуктів тонкої хімії, напівпровідників та зрідженого природного газу. Компанія має 39 заводів у 23 країнах. Ринкова вартість компанії становить близько 1,87 млрд. дол. Її акції котируються на Нью-Йоркській фондовій біржі під абревіатурою СВТ. Доходи компанії за вказаний період наведено на рис. 3.

Мал. 3. Доходи компанії Cabot Corporation у 1982–2001 роках (млрд. дол.)
Як бачимо, довготривала тенденція підвищення доходів затемнена великою кількістю коливань. Таким чином, візуальний аналіз графіка не дозволяє стверджувати, що дані мають тренд. У таких ситуаціях можна застосувати методи ковзного середнього чи експоненційного згладжування.
Ковзаючі середні.Метод ковзних середніх дуже суб'єктивний і залежить від довжини періоду L, вибраного для обчислення середніх значень. Щоб виключити циклічні коливання, довжина періоду має бути цілим числом, кратним середньої довжині циклу. Ковзні середні для вибраного періоду, що має довжину L, утворюють послідовність середніх значень, обчислених для послідовностей довжини L. Ковзаючі середні позначаються символами MA(L).
Припустимо, що ми хочемо обчислити п'ятирічні ковзні середні значення за даними, виміряними протягом n= 11 років. Оскільки L= 5, п'ятирічні ковзні середні утворюють послідовність середніх значень, обчислених по п'яти послідовним значенням часового ряду. Перше з п'ятирічних ковзних середніх значень обчислюється шляхом підсумовування даних про перші п'ять років з наступним розподілом на п'ять:
![]()
Друга п'ятирічна ковзна середня обчислюється шляхом підсумовування даних про роки з 2-го по 6-й з наступним розподілом на п'ять:
![]()
Цей процес триває, доки не буде обчислено ковзну середню для останніх п'яти років. Працюючи з річними даними, слід вважати число L(Довжину періоду, обраного для обчислення ковзних середніх) непарним. У цьому випадку неможливо обчислити ковзні середні для перших ( L– 1)/2 та останніх ( L- 1) / 2 років. Отже, при роботі з п'ятирічними ковзними середніми неможливо виконати обчислення для перших двох та останніх двох років. Рік, для якого обчислюється ковзне середнє, повинен знаходитися в середині періоду, що має довжину L. Якщо n= 11, a L= 5, перше ковзне середнє має відповідати третьому року, друге - четвертому, а останнє - дев'ятому. На рис. 4 показані графіки 3- та 7-річних ковзних середніх, обчислені для доходів компанії Cabot Corporation за період з 1982 по 2001 роки.

Мал. 4. Графіки 3- та 7-річних ковзних середніх, обчислені для доходів компанії Cabot Corporation
Зверніть увагу на те, що при обчисленні трирічних ковзних середніх проігноровані значення, що відповідають першому і останньому рокам. Аналогічно при обчисленні семирічних ковзних середніх немає результатів для перших та останніх трьох років. Крім того, семирічні середні ковзаючі набагато більше згладжують тимчасовий ряд, ніж трирічні. Це тому, що семирічним ковзним середнім відповідає більш тривалий період. На жаль, чим більша довжина періоду, тим менша кількість ковзних середніх можна обчислити та уявити на графіку. Отже, більше семи років для обчислення ковзних середніх вибирати небажано, оскільки з початку і кінця графіка випаде занадто багато точок, що спотворить форму часового ряду.
Експонентне згладжування.Для виявлення довгострокових тенденцій, що характеризують зміни даних, крім ковзних середніх, застосовується метод експоненційного згладжування. Цей метод дозволяє робити короткострокові прогнози (у межах періоду), коли наявність довгострокових тенденцій залишається під питанням. Завдяки цьому метод експоненційного згладжування має значну перевагу над методом ковзних середніх.
Метод експоненційного згладжування отримав свою назву від послідовності експоненційно зважених ковзних середніх. Кожне значення в цій послідовності залежить від усіх попередніх значень, що спостерігаються. Ще одна перевага методу експонентного згладжування над методом ковзного середнього полягає в тому, що при використанні останнього деякі значення відкидаються. При експоненційному згладжуванні ваги, привласнені спостеріганим значенням, зменшуються з часом, тому після виконання обчислень найбільш часто зустрічаються значення отримають найбільшу вагу, а рідкісні величини - найменшу. Незважаючи на величезну кількість обчислень, Excel дозволяє реалізувати метод експонентного згладжування.
Рівняння, що дозволяє згладити тимчасовий ряд у межах довільного періоду часу iмістить три члени: поточне спостерігається значення Yi, що належить тимчасовому ряду, попереднє експоненційно згладжене значення Ei –1 і привласнена вага W.
(3) E 1 = Y 1 E i = WY i + (1 – W)E i–1 , i = 2, 3, 4, …
де Ei– значення експоненційно згладженого ряду, обчислене для i-го періоду, E i –1 – значення експоненційно згладженого ряду, обчислене для ( i- 1)-го періоду, Y i- Спостережуване значення тимчасового ряду в i-ом періоді, W– суб'єктивна вага, або коефіцієнт, що згладжує (0< W < 1).
Вибір коефіцієнта, що згладжує, або ваги, привласненого членам ряду, є принципово важливим, оскільки він безпосередньо впливає на результат. На жаль, цей вибір певною мірою суб'єктивний. Якщо дослідник хоче просто виключити з часового ряду небажані циклічні чи випадкові коливання, слід вибирати невеликі величини W(Близькі до нуля). З іншого боку, якщо тимчасовий ряд використовується для прогнозування, необхідно вибрати велику вагу W(Близький до одиниці). У першому випадку чітко виявляються довгострокові тенденції часового ряду. У другий випадок підвищується точність короткострокового прогнозування (рис. 5).

Мал. 5 Графіки експоненційно згладженого часового ряду (W=0,50 та W=0,25) для даних про доходи компанії Cabot Corporation за період з 1982 по 2001 роки; формули розрахунку див. у файлі Excel
Експонентно згладжене значення, отримане для i-го часового інтервалу, можна використовувати як оцінку передбаченого значення ( i+1)-му інтервалі:
![]()
Для передбачення доходів компанії Cabot Corporation у 2002 році на основі експоненційно згладженого часового ряду, що відповідає вазі W= 0,25 можна використовувати згладжене значення, обчислене для 2001 року. З рис. 5 видно, що ця величина дорівнює 1651,0 млн. дол. Коли стануть доступними дані про доходи компанії у 2002 році, можна застосувати рівняння (3) та передбачити рівень доходів у 2003 році, використовуючи згладжене значення доходів у 2002 році:
Пакет аналізу Excel здатний побудувати графік експонентного згладжування в один клік. Пройдіть меню Дані → Аналіз данихта виберіть опцію Експонентне згладжування(Рис. 6). У вікні, що відкрилося Експонентне згладжуваннявстановіть параметри. На жаль, процедура дозволяє побудувати лише один згладжений ряд, тому якщо ви хочете «пограти» з параметром W, повторіть процедуру.

Мал. 6. Побудова графіка експонентного згладжування за допомогою Пакету аналізу
Обчислення трендів за допомогою методу найменших квадратів та прогнозування
Серед компонентів часового ряду найчастіше досліджується тренд. Саме тренд дозволяє робити короткострокові та довгострокові прогнози. Для виявлення довгострокової тенденції зміни часового ряду зазвичай будують графік, на якому дані (значення залежної змінної), що спостерігаються, відкладаються на вертикальній осі, а часові інтервали (значення незалежної змінної) - на горизонтальній. У цьому розділі ми опишемо процедуру виявлення лінійного, квадратичного та експонентного тренду за допомогою методу найменших квадратів.
Модель лінійного трендує найпростішою моделлю, яка застосовується для прогнозування: Y i = β 0 + β 1 X i + ε i . Рівняння лінійного тренду:
![]()
При заданому рівні значимості нульова гіпотеза відхиляється, якщо тестова t-Статистика більше верхнього або менше нижнього критичного рівня t-Розподілу. Інакше висловлюючись, вирішальне правило формулюється так: якщо t > tUабо t < t Lнульова гіпотеза Н 0відхиляється, інакше нульова гіпотеза не відхиляється (рис. 14).

Мал. 14. Області відхилення гіпотези для двостороннього критерію значимості параметра авторегресії Ар, що має найвищий порядок
Якщо нульова гіпотеза ( Ар= 0) не відхиляється, отже, вибрана модель містить надто багато параметрів. Критерій дозволяє відкинути старший член моделі та оцінити авторегресійну модель порядку р-1. Цю процедуру слід продовжувати доти, доки нульова гіпотеза Н 0не буде відхилено.
- Виберіть порядок роцінюваної авторегресійної моделі з урахуванням того, що t-Критерій значимості має n-2р-1степенів свободи.
- Сформуйте послідовність змінних р«із запізненням» так, щоб перша змінна запізнювалася на один часовий інтервал, друга - на два і так далі. Останнє значення має запізнюватися на ртимчасових інтервалів (див. рис. 15).
- Застосуйте Пакет аналізу Excel для обчислення регресійної моделі, що містить усі рзначень часового ряду із запізненням.
- Оцініть важливість параметра А Р, що має найвищий порядок: а) якщо нульова гіпотеза відхиляється, до авторегресійної моделі можна включати все рпараметрів; б) якщо нульова гіпотеза не відхиляється, відкиньте р-ю змінну і повторіть п.3 та 4 для нової моделі, що включає р-1параметр. Перевірка значимості нової моделі заснована на t-Критерії, кількість ступенів свободи визначається новою кількістю параметрів.
- Повторюйте п.3 і 4, поки старший член авторегресійної моделі стане статистично значущим.
Щоб продемонструвати авторегресійне моделювання, повернемося до аналізу часового ряду реальних доходів компанії Wm. Wrigley Jr. На рис. 15 показані дані, необхідні для побудови авторегресійних моделей першого, другого та третього порядку. Для побудови моделі третього порядку потрібні всі стовпці цієї таблиці. При побудові авторегресійної моделі другого порядку останній стовпець ігнорується. При побудові авторегресійної моделі першого порядку ігноруються два останні стовпці. Таким чином, при побудові авторегресійних моделей першого, другого та третього порядку з 20 змінних виключаються одна, дві та три відповідно.

Вибір найбільш точної авторегресійної моделі починається з моделі третього порядку. Для коректної роботи Пакет аналізуслід як вхідний інтервал Yвказати діапазон В5:В21, а вхідного інтервалу для Х- С5: Е21. Дані аналізу наведено на рис. 16.

Перевіримо важливість параметра А 3, що має найвищий лад. Його оцінка а 3дорівнює -0,006 (комірка С20 на рис. 16), а стандартна помилка дорівнює 0,326 (комірка D20). Для перевірки гіпотез Н 0: А 3 = 0 та Н 1: А 3 ≠ 0 обчислимо t-Статистику:

t-критерія з n-2p-1 = 20-2 * 3-1 = 13 ступенями свободи рівні: t L=СТЬЮДЕНТ.ОБР(0,025;13) = -2,160; t U=СТЬЮДЕНТ.ОБР(0,975;13) = +2,160. Оскільки -2,160< t = –0,019 < +2,160 и р= 0,985 > α = 0,05, нульову гіпотезу Н 0відхиляти не можна. Таким чином, параметр третього порядку не має статистичної значущості в авторегресійній моделі і повинен бути видалений.
Повторимо аналіз для авторегресійної моделі другого порядку (рис. 17). Оцінка параметра, що має найвищий порядок, а 2= –0,205, та її стандартна помилка дорівнює 0,276. Для перевірки гіпотез Н 0: А 2 = 0 та Н 1: А 2 ≠ 0 обчислимо t-Статистику:


При рівні значимості α = 0,05, критичні величини двостороннього t-критерія з n-2p-1 = 20-2 * 2-1 = 15 ступенями свободи рівні: t L=СТЬЮДЕНТ.ОБР(0,025;15) = -2,131; t U=СТЬЮДЕНТ.ОБР(0,975;15) = +2,131. Оскільки -2,131< t = –0,744 < –2,131 и р= 0,469 > α = 0,05, нульову гіпотезу Н 0відхиляти не можна. Таким чином, параметр другого порядку не є статистично значущим, його слід видалити з моделі.
Повторимо аналіз для авторегресійної моделі першого порядку (рис. 18). Оцінка параметра, що має найвищий порядок, а 1= 1,024, та її стандартна помилка дорівнює 0,039. Для перевірки гіпотез Н 0: А 1 = 0 та Н 1: А 1 ≠ 0 обчислимо t-Статистику:


При рівні значимості α = 0,05, критичні величини двостороннього t-критерія з n-2p-1 = 20-2 * 1-1 = 17 ступенями свободи рівні: t L=СТЬЮДЕНТ.ОБР(0,025;17) = -2,110; t U=СТЬЮДЕНТ.ОБР(0,975;17) = +2,110. Оскільки -2,110< t = 26,393 < –2,110 и р = 0,000 < α = 0,05, нулевую гипотезу Н 0слід відхилити. Таким чином, параметр першого порядку є статистично значущим і його не можна видаляти з моделі. Отже, модель авторегресії першого порядку краще за інших апроксимує вихідні дані. Використовуючи оцінки а 0 = 18,261, а 1= 1,024 і значення часового ряду за останній рік - Y 20 = 1371,88, можна передбачити величину реальних доходів компанії Wm. Wrigley Jr. Company у 2002 р.:
Вибір адекватної моделі прогнозування
Вище було описано шість методів прогнозування значень тимчасового ряду: моделі лінійного, квадратичного та експоненційного трендів та авторегресійні моделі першого, другого та третього порядків. Чи є оптимальна модель? Яку із шести описаних моделей слід застосовувати для прогнозування значення часового ряду? Нижче наведено чотири принципи, якими необхідно керуватися при виборі адекватної моделі прогнозування. Ці принципи ґрунтуються на оцінках точності моделей. У цьому передбачається, що значення часового ряду можна передбачити, вивчаючи попередні значення.
Принципи вибору моделей для прогнозування:
- Виконайте аналіз залишків.
- Оцініть величину залишкової помилки за допомогою квадратів різниці.
- Оцініть величину залишкової помилки за допомогою абсолютних різниць.
- Керуйтеся принципом економії.
Аналіз залишків.Нагадаємо, що залишком називається різниця між передбаченим і спостережуваним значенням. Побудувавши модель для тимчасового ряду, слід обчислити залишки для кожного з nінтервалів. Як показано на рис. 19, панель А, якщо модель є адекватною, залишки є випадковим компонентом часового ряду і, отже, розподілені нерегулярно. З іншого боку, як показано на інших панелях, якщо модель не адекватна, залишки можуть мати систематичну залежність, яка не враховує або тренд (панель Б), циклічний (панель В), або сезонний компонент (панель Г).

Мал. 19. Аналіз залишків
Вимірювання абсолютної та середньоквадратичної залишкових похибок.Якщо аналіз залишків не дозволяє визначити єдину адекватну модель, можна скористатися іншими методами, що ґрунтуються на оцінці величини залишкової похибки. На жаль, статистики не дійшли консенсусу щодо найкращої оцінки залишкових похибок моделей, які застосовуються для прогнозування. Виходячи з принципу найменших квадратів, можна спочатку провести регресійний аналіз та обчислити стандартну помилку оцінки S XY. При аналізі конкретної моделі ця величина є сумою квадратів різниць між фактичним і передбаченим значеннями часового ряду. Якщо модель ідеально апроксимує значення часового ряду в попередні моменти часу, стандартна помилка оцінки дорівнює нулю. З іншого боку, якщо модель погано апроксимує значення часового ряду попередніх моментів часу, стандартна помилка оцінки велика. Таким чином, аналізуючи адекватність кількох моделей, можна вибрати модель, що має мінімальну стандартну помилку оцінки S XY.
Основним недоліком такого підходу є перебільшення помилок під час прогнозування окремих значень. Інакше кажучи, будь-яка велика різниця між величинами Yiі Ŷ iпри обчисленні суми квадратів помилок SSE зводиться квадрат, тобто. збільшується. З цієї причини багато статистики вважають за краще застосовувати для оцінки адекватності моделі прогнозування середнє абсолютне відхилення (mean absolute deviation - MAD):

При аналізі конкретних моделей величина MAD є середнє значення модулів різниць між фактичним і передбаченими значеннями часового ряду. Якщо модель ідеально апроксимує значення часового ряду в попередні моменти часу, середнє абсолютне відхилення дорівнює нулю. З іншого боку, якщо модель погано апроксимує такі значення часового ряду, середнє абсолютне відхилення велике. Таким чином, аналізуючи адекватність декількох моделей, можна вибрати модель, що має мінімальне абсолютне середнє відхилення.
Принцип економії.Якщо аналіз стандартних помилок оцінок та середніх абсолютних відхилень не дозволяє визначити оптимальну модель, можна скористатися четвертим методом, що базується на принципі економії. Цей принцип стверджує, що з кількох рівноправних моделей слід обирати найпростішу.
Серед шести розглянутих на чолі моделей прогнозування найпростішими є лінійна та квадратична регресійні моделі, а також авторегресійна модель першого порядку. Інші моделі набагато складніші.
Порівняння чотирьох методів прогнозування.Для ілюстрації процесу вибору оптимальної моделі повернемося до тимчасового ряду, що складається з реального доходу компанії Wm. Wrigley Jr. Company. Порівняємо чотири моделі: лінійну, квадратичну, експоненційну та авторегресійну модель першого порядку. (Авторегресійні моделі другого і третього порядку лише трохи покращують точність прогнозування значень даного тимчасового ряду, тому їх можна не розглядати.) На рис. 20 показані графіки залишків, побудовані під час аналізу чотирьох методів прогнозування за допомогою Пакет аналізу Excel. Роблячи висновки з урахуванням цих графіків, слід бути обережним, оскільки тимчасовий ряд містить лише 20 точок. Методи побудови див. відповідний аркуш Excel-файлу.

Мал. 20. Графіки залишків, побудовані під час аналізу чотирьох методів прогнозування за допомогою Пакет аналізу Excel
Жодна модель, крім авторегресійної моделі першого порядку, не враховує циклічний компонент. Саме ця модель краще за інших апроксимує спостереження і характеризується найменш систематичною структурою. Отже, аналіз залишків всіх чотирьох методів показав, що найкращою є авторегресійна модель першого порядку, а лінійна, квадратична та експоненційна моделі мають меншу точність. Щоб у цьому, порівняємо величини залишкових похибок цих методів (рис. 21). З методикою розрахунків можна ознайомитись, відкривши Excel-файл. На рис. 21 вказані фактичні значення Y i(колонка Реальний дохід), передбачені значення Ŷ i, а також залишки еiдля кожної із чотирьох моделей. Крім того, показано значення SYXі MAD. Для всіх чотирьох моделей величин SYXі MADприблизно однакові. Експоненційна модель є відносно гіршою, а лінійна та квадратична моделі перевершують її за точністю. Як і очікувалося, найменші величини SYXі MADмає авторегресійну модель першого порядку.

Мал. 21. Порівняння чотирьох методів прогнозування за допомогою показників S YX та MAD
Вибравши конкретну модель прогнозування, необхідно уважно стежити подальші зміни часового ряду. Крім того, така модель створюється, щоб правильно передбачати значення тимчасового ряду в майбутньому. На жаль, такі моделі прогнозування погано враховують зміни у структурі часового ряду. Цілком необхідно порівнювати як залишкову похибку, а й точність прогнозування майбутніх значень часового ряду, отриману з допомогою інших моделей. Вимірявши нову величину Yiв інтервалі часу, що спостерігається, її необхідно відразу ж порівняти з передбаченим значенням. Якщо різниця занадто велика, модель прогнозування слід переглянути.
Прогнозування часів ых рядів на основі сезонних даних
До цього часу ми вивчали тимчасові ряди, які з річних даних. Однак багато тимчасових рядів складаються з величин, що вимірюються щокварталу, щомісяця, щотижня, щодня і навіть щогодини. Як показано на рис. 2, якщо дані вимірюються щомісяця чи щокварталу, слід враховувати сезонний компонент. У цьому розділі ми розглянемо методи, що дають змогу прогнозувати значення таких часових рядів.
У сценарії, описаному на початку глави, згадувалася компанія Wal-Mart Stores, Inc. Ринкова капіталізація компанії 229 млрд. дол. Її акції котируються на Нью-Йоркській фондовій біржі під абревіатурою WMT. Фінансовий рік компанії закінчується 31 січня, тому до четвертого кварталу 2002 року включаються листопад та грудень 2001 року, а також січень 2002 року. Тимчасовий ряд квартальних доходів компанії наведено на рис. 22.

Мал. 22. Квартальні прибутки компанії Wal-Mart Stores, Inc. (Млн. дол.)
Для таких квартальних рядів, як цей, класична мультиплікативна модель, крім тренду, циклічного та випадкового компонента, містить сезонний компонент: Y i = T i* S i* C i* I i
Прогнозування місячних і тимчасових ых рядів за допомогою методу найменших квадратів.Регресійна модель, що включає сезонний компонент, ґрунтується на комбінованому підході. Для обчислення тренду застосовується метод найменших квадратів, описаний раніше, а для обліку сезонного компонента – категорійна змінна (докладніше див. Регресійні моделі з фіктивною змінною та ефекти взаємодії). Для апроксимації часових рядів із урахуванням сезонних компонентів використовується експоненційна модель. У моделі, що апроксимує квартальний часовий ряд, для обліку чотирьох кварталів нам знадобилися три фіктивні змінні. Q 1, Q 2і Q 3, а моделі для місячного часового ряду 12 місяців представляються з допомогою 11 фіктивних змінних. Оскільки в цих моделях як відгук використовується змінна log Y i, а не Y i, для обчислення реальних регресійних коефіцієнтів потрібно здійснити зворотне перетворення.
Щоб проілюструвати процес побудови моделі, що апроксимує квартальний часовий ряд, повернемося до доходів компанії Wal-Mart. Параметри експоненційної моделі, отримані за допомогою Пакет аналізу Excel показано на рис. 23.

Мал. 23. Регресійний аналіз квартальних доходів компанії Wal-Mart Stores, Inc.
Видно, що експоненційна модель досить добре апроксимує вихідні дані. Коефіцієнт змішаної кореляції r 2 дорівнює 99,4% (комірки J5), скоригований коефіцієнт змішаної кореляції - 99,3% (комірки J6), тестова F-статистика - 1333,51 (осередки M12), а р-значення дорівнює 0,0000. При рівні значимості α = 0,05, кожен регресійний коефіцієнт класичної мультиплікативної моделі часового ряду є статистично значущим. Застосовуючи до них операцію потенціювання, отримуємо такі параметри:

Коефіцієнти ![]() інтерпретуються в такий спосіб.
інтерпретуються в такий спосіб.
Використовуючи регресійні коефіцієнти b i, можна передбачити дохід, отриманий компанією у конкретному кварталі. Наприклад, передбачимо дохід компанії для четвертого кварталу 2002 року ( Xi = 35):
log = b 0 + b 1 Хi = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Таким чином, згідно з прогнозом у четвертому кварталі 2002 року компанія мала отримати дохід, рівний 67 млрд. дол. (навряд чи слід робити прогноз з точністю до мільйона). Для того щоб поширити прогноз на період часу, що знаходиться за межами часового ряду, наприклад, на перший квартал 2003 року ( Xi = 36, Q 1= 1), необхідно виконати такі обчислення:
log Ŷ i = b 0 + b 1Хi + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Індекси
Індекси використовуються як індикатори, що реагують на зміни економічної ситуації або ділової активності. Існують численні різновиди індексів, зокрема індекси цін, кількісні індекси, ціннісні індекси та соціологічні індекси. У цьому розділі ми розглянемо лише індекс цін. Індекс- величина деякого економічного показника (або групи показників) у конкретний момент часу, виражений у відсотках від його значення у базовий момент часу.
Індекс цін.Простий індекс цін відображає відсоткову зміну ціни товару (або групи товарів) протягом заданого періоду часу порівняно з ціною цього товару (або групи товарів) у конкретний момент часу минулого. При обчисленні індексу цін перш за все слід вибрати базовий проміжок часу - інтервал часу в минулому, з яким проводитимуться порівняння. При виборі базового проміжку часу для конкретного індексу періоди економічної стабільності є кращими порівняно з періодами економічного підйому або спаду. Крім того, базовий проміжок не повинен бути надто віддаленим у часі, щоб на результати порівняння не надто сильно впливали зміни технології та звичок споживачів. Індекс цін обчислюється за такою формулою:

де I i- індекс цін у i-му році, Рi- ціна в i-му році, Р баз- ціна у базовому році.
Індекс цін - відсоткова зміна ціни товару (або групи товарів) у заданий період часу стосовно ціни товару у базовий момент часу. Як приклад, розглянемо індекс цін на неетильований бензин у США в проміжку часу з 1980 по 2002 р. (рис. 24). Наприклад:


Мал. 24. Ціна галону неетильованого бензину та простий індекс цін у США з 1980 по 2002 р. (базові роки - 1980 та 1995)
Отже, 2002 р. ціна неэтилированного бензину США була на 4,8% більше, ніж 1980 р. Аналіз рис. 24 показує, що індекс цін 1981 і 1982 гг. був більший за індекс цін у 1980 р., а потім аж до 2000 року не перевищував базового рівня. Оскільки як базовий період обрано 1980 р., ймовірно, має сенс вибрати найближчий рік, наприклад, 1995 р. Формула для перерахунку індексу по відношенню до нового базового проміжку часу:

де Iновий- Новий індекс цін, Iстарий- Старий індекс цін, Iновабаза – значення індексу цін новому базовому року під час розрахунку для старого базового року.
Припустимо, що в якості нової бази обрано 1995 рік. Використовуючи формулу (10), отримуємо новий індекс цін на 2002 рік:
Отже, 2002 р. неетильований бензин у США коштував на 13,9% більше, ніж 1995 р.
Незважені складові індекси цін.Незважаючи на те, що індекс цін на будь-який окремий товар представляє безперечний інтерес, важливішим є індекс цін на групу товарів, що дозволяє оцінити вартість і рівень життя великої кількості споживачів. Незважений складовий індекс цін, визначений формулою (11), приписує кожному окремому виду товарів однакову вагу. Складовий індекс цін відбиває відсоткове зміна ціни групи товарів (часто званої споживчою кошиком) у заданий період по відношенню до ціні цієї групи товарів у базовий час.

де t i- номер товару (1, 2, …, n), n- кількість товарів у групі, що розглядається, - сума цін на кожен з nтоварів у період часу t, - сума цін на кожен з nтоварів у нульовий період часу, - величина незваженого складового індексу у період часу t.
На рис. 25 представлені середні ціни на три види фруктів за період із 1980 по 1999 роки. Для обчислення незваженого складового індексу цін у роки застосовується формула (11), вважаючи базовим 1980 рік.
Отже, у 1999 р. сумарна ціна фунта яблук, фунта бананів та фунта апельсинів на 59,4% перевищувала сумарну ціну на ці фрукти у 1980 р.

Мал. 25. Ціни (у дол.) на три види фруктів та незважений складовий індекс цін
Незважений складовий індекс цін виражає зміни ціни всю групу товарів із часом. Незважаючи на те, що цей індекс легко обчислювати, у нього є дві явні недоліки. По-перше, при обчисленні цього індексу всі види товарів вважаються однаково важливими, тому дорогі товари набувають надмірного впливу на індекс. По-друге, не всі товари споживаються однаково інтенсивно, тому зміни цін на товари, що мало споживаються, надто сильно впливають на незважений індекс.
Виважені складові індекси цін.Через недоліки невважених індексів цін кращими є зважені індекси цін, що враховують відмінності цін і рівнів споживання товарів, що утворюють споживчий кошик. Існують два типи зважених складових індексів цін. Індекс цін Лапейре, визначений формулою (12), використовує рівні споживання у базовому році. Зважений складовий індекс цін дозволяє врахувати рівні споживання товарів, що утворюють споживчий кошик, привласнюючи кожному товару певну вагу.

де t- період часу (0, 1, 2, …), i- номер товару (1, 2, …, n), n iв нульовий період часу - значення індексу Лапейре в період часу t.
Обчислення індексу Лапейре показано на рис. 26; як базовий використовується 1980 рік.

Мал. 26. Ціни (у дол.), кількість (споживання в фунтах на душу населення) трьох видів фруктів та індекс Лапейре
Отже, індекс Лапейре 1999 р. дорівнює 154,2. Це свідчить про те, що у 1999 році ці три види фруктів були на 54,2% дорожчими, ніж у 1980 році. Зверніть увагу на те, що цей індекс менший за незважений індекс, що дорівнює 159,4, оскільки ціни на апельсини - фрукти, що споживаються менше інших, - зросли більше, ніж ціна яблук і бананів. Інакше кажучи, оскільки ціни на фрукти, що споживаються найбільш інтенсивно, зросли менше, ніж ціни на апельсини, індекс Лапейре менший за незважений складовий індекс.
Індекс цін Паашевикористовує рівні споживання товару у поточному, а чи не базовому періоді часу. Отже, індекс Пааше більш точно відбиває повну вартість споживання товарів у заданий час. Однак цей індекс має дві істотні недоліки. По-перше, зазвичай поточні рівні споживання важко визначити. З цієї причини багато популярних індексів використовують індекс Лапейре, а не індекс Пааше. По-друге, якщо ціна деякого конкретного товару, що входить до споживчого кошика, різко зростає, покупці знижують рівень його споживання за потребою, а не внаслідок зміни смаків. Індекс Пааше обчислюється за такою формулою:

де t- період часу (0, 1, 2, …), i- номер товару (1, 2, …, n), n- кількість товарів у групі, що розглядається, - кількість одиниць товару iв нульовий період часу - значення індексу Пааше в період часу t.
Обчислення індексу Пааше показано на рис. 27; як базовий використовується 1980 рік.

Мал. 27. Ціни (у дол.), кількість (споживання в фунтах на душу населення) трьох видів фруктів та індекс Пааше
Отже, індекс Пааше 1999 р. дорівнює 147,0. Це свідчить про те, що у 1999 році ці три види фруктів були на 47,0% дорожчими, ніж у 1980 році.
Деякі популярні індекси цін.У бізнесі та економіці використовується кілька індексів цін. Найбільш популярним є індекс споживчих цін (Consumer Index Price – CPI). Офіційно цей індекс називається CPI-U, щоб наголосити, що він обчислюється для міст (urban), хоча, як правило, його називають просто CPI. Цей індекс щомісяця публікується Бюро статистики праці (US Bureau of Labor Statistics) як основний інструмент для вимірювання вартості життя в США. Індекс споживчих цін є складовим та виваженим за методом Лапейре. При його обчисленні використовуються ціни 400 продуктів, видів одягу, транспортних, медичних і комунальних послуг, що найбільш широко споживаються. На даний момент при обчисленні цього індексу як базовий використовується період 1982-1984 років. (Рис. 28). Важливою функцією індексу CPI є його використання як дефлятор. Індекс CPI використовується для перерахунку фактичних цін на реальні шляхом множення кожної ціни на коефіцієнт 100/CPI. Розрахунки показують, що за останні 30 років середньорічні темпи інфляції у США становили 2,9%.

Мал. 28. Динаміка Consumer Index Price; повні дані див. Excel-файл
Іншим важливим індексом цін, що публікується Бюро статистики праці, є індекс цін виробників (Producer Price Index – PPI). Індекс PPI є виваженим складовим індексом, який використовує метод Лапейре для оцінки зміни цін товарів, що їх продавалися виробниками. Індекс PPI є індикатором для індексу CPI. Інакше кажучи, збільшення індексу PPI призводить до збільшення індексу CPI і навпаки, зменшення індексу PPI призводить до зменшення індексу CPI. Фінансові індекси, такі як індекс Доу-Джонса для акцій промислових підприємств (Dow Jones Industrial Average – DJIA), S&P 500 та NASDAQ, використовуються для оцінки зміни вартості акцій у США. Багато індексів дозволяють оцінити прибутковість міжнародних фондових ринків. До таких індексів відносяться індекс Nikkei у Японії, Dax 30 у Німеччині та SSE Composite у Китаї.
Пастки, пов'язані з аналізом часу ых рядів
Значення методології, що використовує інформацію про минуле і сьогодення для того, щоб прогнозувати майбутнє, понад двісті років тому красномовно описав державний діяч Патрік Генрі: «Я маю лише одну лампу, яка висвітлює шлях, - мій досвід. Тільки знання минулого дозволяє судити про майбутнє».
Аналіз часових рядів ґрунтується на припущенні, що фактори, що впливали на ділову активність у минулому та впливають на сьогодення, діятимуть і в майбутньому. Якщо це правда, аналіз часових рядів є ефективним засобом прогнозування та управління. Проте критики класичних методів, заснованих на аналізі часових рядів, стверджують, що ці методи надто наївні та примітивні. Інакше кажучи, математична модель, яка враховує фактори, що діяли в минулому, не повинна механічно екстраполювати тренди в майбутнє без урахування експертних оцінок, досвіду ділової активності, зміни технології, звичок і потреб людей. Намагаючись виправити це становище, останніми роками фахівці з економетрії розробляли складні комп'ютерні моделі економічної активності, які враховують перелічені вище чинники.
Тим не менш, методи аналізу часових рядів є чудовим інструментом прогнозування (як короткострокового, так і довгострокового), якщо вони застосовуються правильно, у поєднанні з іншими методами прогнозування, а також з урахуванням експертних оцінок і досвіду.
РезюмеУ замітці за допомогою аналізу часових рядів розроблено моделі для прогнозування доходів трьох компаній: Wm. Wrigley Jr. Company, Cabot Corporation та Wal-Mart. Описані компоненти тимчасового ряду, а також кілька підходів до прогнозування річних тимчасових рядів – метод ковзних середніх, метод експоненційного згладжування, лінійна, квадратична та експоненційна моделі, а також авторегресійна модель. Розглянуто регресійну модель, що містить фіктивні змінні, що відповідають сезонному компоненту. Показано застосування методу найменших квадратів для прогнозування місячних та квартальних часових рядів (рис. 29).
Р ступенів свободи втрачаються при порівнянні значень часового ряду.

